Magic Quadrant for Enterprise Backup / Recovery
Não é uma grande surpresa, vendo como serviço de supercomputação nacional do Reino Unido na Universidade de Edimburgo é um cliente Cray de longa data, que eles voltariam para Cray para substituir seu sistema XE6 existente e substituí-lo por uma máquina petaflops de classe com base nas últimas interconexão Cray e tecnologia de processador Intel.
A nova máquina, a ser chamado de "Archer", será baseado no mais recente XC30 ferro da Cray, que processadores E5 Xeon de pares Intel com o "Aries" de interconexão desenvolvido pela fabricante de supercomputadores por meio de um contrato com a Defense Advanced Research Projects Agency dos EUA.
A Engenharia e Ciências Físicas Research Council está fornecendo a US $ 30 milhões em financiamento para o sistema de Archer, que inclui uma caixa de produção com cerca de três vezes o desempenho do sistema existente XE6, que tem mais de 800 teraflops de agregar glamour números impressionantes e é apelidado "Hector" - na verdade, eles feitiço que "HECToR", para High-End Computing TeraScale Resource, mas não vamos ser arrastados para tal tolice ortográfica.
Os detalhes de configuração precisos para o sistema não foram fornecidos pela Cray ou da Universidade de Edimburgo, muito provavelmente porque a máquina será baseada nos como ainda não anunciado "Ivy Bridge-EP" Xeon E5 da Intel. No início deste ano, Chipzilla disse esperar que os chips Xeon E5 para ser lançado no terceiro trimestre, e os primeiros embarques para a nuvem chave e clientes de supercomputadores para os Ivy Bridge variantes destes chips começou há vários meses.
O sistema é composto por Hector armários 30, que têm um total de 704 de quatro nós servidores blade XE6 da Cray. Cada nó na lâmina tem duas dezesseis soquetes "Interlagos" 6276 processadores Opteron rodando a 2.3GHz. Cada tomada na lâmina XE6 tem 16GB de memória principal, e com 2.816 nós de computação, que trabalha fora de 90.112 núcleos e 88TB de memória principal.
A lâmina XE6 tem quatro "Gemini" chips de interconexão do roteador, que implementam um toro 3D em todos os nós e deixe-a escalar até vários petaflops. A máquina Hector também tem um sistema de arquivos em cluster Lustre que as escalas para mais de 1 PB de capacidade.
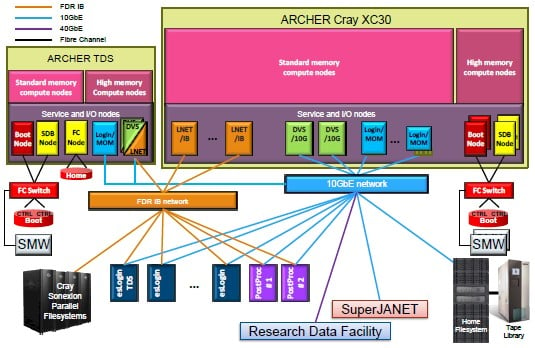
Esquema do desenvolvimento de Archer e sistemas de produção de HPC
O XC30 supercomputador, desenvolvido sob o codinome "Cascade" por Cray com financiamento do programa de Sistemas de Computação de Alta Produtividade da DARPA, começou uma década atrás. Que o financiamento veio em duas fases, com a quantia inicial de US $ 43.1m sendo usado para descrever como Cray iriam convergir diversas máquinas baseadas em x86, vetor, FPGA, e MTA processadores multithread em uma única plataforma. (GPU coprocessors não havia se tornado uma coisa ainda em 2003, quando o prêmio inicial DARPA saiu.)
Três anos mais tarde, a DARPA deu Cray um prémio de investigação US $ 250 milhões para desenvolver o sistema de Cascade e sua Carneiro Dragonfly interconexão, bem como o trabalho sobre a linguagem de programação paralela da Capela. Ninguém fora da Cray ou DARPA sabia disso na época, mas a segunda parte do contrato de DARPA HPCS originalmente chamado de Cray a dar seus processadores vetoriais multitransmissão (quase esquecido neste momento) e seus processadores ThreadStorm multithreads (no coração do aparelho de análise de gráfico Urika) e combiná-los em um superchip.
Mas em janeiro de 2010, a DARPA cortar US $ 60 milhões do contrato de Cascade e Cray focada no muito rápido e expansível interconexão Dragonfly. Todo o projeto custou US $ 233.1m para se desenvolver, e agora Cray tem o direito de vender ferro com base nessa tecnologia.
Cray tem mais US $ 140 milhões em abril de 2012 , quando vendeu a propriedade intelectual para o Gêmeos e Áries interliga a Intel. Cray retém o direito de vender a interconexão Áries e está trabalhando com a Intel no futuro interliga, possivelmente, de codinome "Pisces" e, presumivelmente usada no "Shasta" sistemas massivamente paralelos que Cray e Intel disse que eles estão trabalhando juntos como eles anunciaram a interconexão Carneiro venda.
O importante, tanto quanto a Universidade de Edimburgo está em causa é que o sistema XC30 tem montes e montes de espaço livre - na verdade, um XC30 totalmente carregado é projetado para escalar a bem mais de 100 petaflops. Mas o Reino Unido centro da HPC não vai estar empurrando os limites do XC30 em breve, com o sistema Archer ter um pouco mais de 2 petaflops de glamour. (Quase três vezes o desempenho da máquina Hector, como a Cray declaração explicadas.)
O plano para Archer, de acordo com os documentos de licitação , as chamadas para a universidade para obter um sistema de teste e desenvolvimento, bem como um sistema de produção muito maior, com duas caixas tendo nós de computação com memória padrão, mas com um subconjunto de ter configurações de memória mais gordos.
A 56Gb/sec InfiniBand links de rede para fora aos sistemas de arquivos Sonexion (que tem um total de 4.8TB de capacidade e 100GB/sec de largura de banda para o sistema) e os servidores de login que sentar na frente da máquina Archer produção. Uma rede Ethernet 10Gb/sec ganchos para outro local e armazenagem de arquivo de fita, bem como para outros serviços de rede.
O acordo Archer inclui o custo dos sistemas XC30 eo armazenamento Sonexion, bem como um contrato de serviços multi-ano, tudo vale a pena combinado de US $ 30 milhões. (Sim, este tipo de agregação torna muito difícil descobrir o que o sistema e hardware de armazenamento custa individualmente de serviços, e isso é absolutamente intencional). Archer está previsto para ser colocado em produção este ano.
Como mencionamos anteriormente, centro de HPC do Edinburgh é um cliente Cray de longa data, tendo instalado um sistema paralelo T3D em 1994 e adicionou um sistema T3E em 1996, que atingiu o pico fora em 309 gigaflops (você leu certo), quando foi aposentado em 2002 . ®
Nenhum comentário:
Postar um comentário